2023.07.17
OCRは本当に実用的?現在の精度や向上させるための方法を徹底紹介
画像から文字を認識・読み込める機能を「OCR」といいます。書類や画像を見ながら文字を手打ちするよりも素早く自動でテキスト化できるため、DXやペーパーレスを推進する企業から注目されています。
また、電子帳簿保存法への対応に追われる企業にとってもOCRは重要な位置づけにあるといえます。
今回は、OCRの概要やテキスト化の仕組み、現在のOCRの精度、文字認識精度を高める方法、AI OCRとは何かという点について解説します。ぜひ、ご参考にしてください。

- 目次
OCRとは
例えば、書類や本などの紙文書をテキスト化しようとしたとき、1ページずつ手打ちで入力するのは時間も労力もかかります。またスキャンしたとしても、読み取った箇所は画像として取り込まれるためデータとして活用することはできません。
しかし、OCRを使用すると紙文書に書かれた文字を画像ではなく「文字データ」として取り込めます。これにより、検索もできる汎用性の高いデータとして幅広く利用できるようになるのです。
基本的にOCRの対象は印刷文字ですが、近年では手書き文字を認識できるOCRも開発されています。
なお、OCRについては下記の記事でも触れています。ぜひ、合わせてご覧ください。

AI OCRとは?メリット・注意点・活用事例をご紹介
AI OCRは、従来のOCRよりも高い精度で文字認識が可能です。大量の紙データをデジタルデータに変換したいなら、AI OCRの利用がおすすめです。本記事では、AI OCRの概要やOCRとの違い、導入メリット、注意点などをご紹介します。
OCRで画像がテキスト化される仕組み
1.画像入力
2.前処理
3.文字認識
4.文字の修正と解釈
5.テキスト出力
OCRによっては、読み取った紙書類のレイアウトをPDFに書き出して再現できるものもあります。
現在の OCRの精度

期待以上の成果を求めて導入を決めた方の中にとってはがっかりする結果になったことでしょう。
しかし、OCRの精度は年々向上しています。国立国会図書館の「OCRを用いたデジタル画像の全文テキスト化実施結果報告書」によると、全20,000冊(明治期刊行図書5,000冊、大正刊行図書10,000冊、昭和戦前期刊行図書4,790冊、昭和戦後期刊行図書210冊)の文字認識率の平均認識率は91.3%でした。
|
区分 |
対象冊数 |
ファイル形式 |
解像度 |
階調 |
認識率 |
|
明治期刊行図書 |
5,000冊 |
JPEG2000 |
400dpi |
2値 |
87.7% |
|
大正期刊行図書 |
10,000冊 |
JPEG2000 |
350dpi |
グレイ |
88.2% |
|
昭和戦前期刊行図書 |
4,790冊 |
JPEG2000 |
350dpi |
グレイ |
92.7% |
|
昭和戦後期刊行図書 |
210冊 |
JPEG2000/JPEG |
400dpi |
カラー |
96.6% |
OCRの精度を向上させる方法
高い解像度でスキャンする
高性能のスキャナーを用意する
OCRよりAI OCRの方が精度が良い?

OCRでは誤認しやすい誤字やくせ字、はみだし字、手書き文字でもAI OCRにおいては高い処理精度が期待できるため、これからOCRを導入しようと考えているならAI OCRに注目することもおすすめします。
JBAT「ペーパーレスソリューション」導入事例
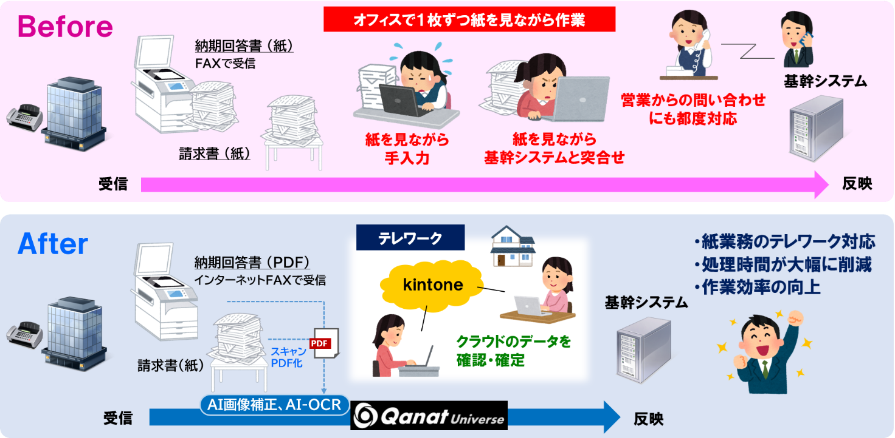
JBグループ業務センターの毎月900件の請求書処理をテレワークで実現
JBグループ業務センターでは、取引先からの紙の請求書や、FAXでやりとりしていた納期回答書をPDF化し、様々な製品やサービスをつなぐクラウドプラットフォーム「Qanat Universe」に取り込みます。毎月900件の請求書の処理を自動化する他、手書きの納期回答書への対応も可能にしています。

FAX受注業務をkintone とQanat Universeペーパーレスソリューションで自動化、作業時間4割削減
株式会社文理様は、取引先からFAX で送られてくる注文書をOCRで読み込みデジタル化することに成功。取引先の業務を変えずにどのように受注処理を改善したのか。バックオフィス業務を取りまとめる担当者の方と情報システム課としてシステム構築に携わった担当者の方にお話を伺いました。
まとめ
企業のあらゆる紙業務を自動化!
やりたいことをスピーディに実現!
Qanat Universeペーパーレスソリューション は、
紙にかかわる業務プロセスを
全て解決します

クラウドプラットフォーム「Qanat Universe」なら
目的に合わせてやりたいことを柔軟かつスピーディに対応
●AIOCR
高精度OCR

最先端のAI技術による99.2%の
読み取り精度
あらゆる紙のデータ化をアシスト
●電子ノート
書いた文字のデジタル化

最長2週間稼働の省電力
368gの超軽量電子ノート
データ連携で紙業務をデジタル化
●QUスキャナー
高速読み取り&PDF化

毎分80枚の高速読み込み性能
クラウドと直接つないで
業務プロセスを自動化
請求処理の電子帳簿保存法への対応、IT化出来ない過酷な環境での紙の記入業務
様々な紙の課題を解決し、お客様の時間を創出します!
是非一度お悩みや、お話をお聞かせください
>>詳細はこちら




